Brute force
Checking all substrings will take time 
Observations
We can use divide-and-conquer in two ways to simplify the counting problem:
- Each char in a good subsequence appears the same number of times. If in the input
str, the charhas the max frequency
, then we can partition the good subsequences in
- There are total
subsequences of a
-length str. Say, there are m types of char. So,
. We note that
. Therefore, we can count the possible subsequences for each type of char separately and then multiply them together. The interleaving of these different char’s in the input does not affect the total count. We can use this idea to count
-length good subsequences having a single char type. Then, the product of the counts for each distinct char in the alphabet will be the total count of good subsequences having
str. For example, if there are three‘s and four
‘s, the count of 2-length good subsequences having
and the count of 2-length good subsequences having
. Now, we can multiply these two counts to have the total count of good subsequences having two
s and two
s.
Count of good subsequences with 



For each
Efficiency of computing 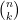
Dynamic Programming
Subproblem

Order
Subproblems are on a grid. Edges flow from subproblems on an earlier row and on an earlier (or current) column. So, we process in increasing order of row (
Time: 
class Solution:
def countGoodSubsequences(self, s: str) -> int:
mod = pow(10, 9)+7
alphabet = [ chr( ord('a')+offset ) for offset in range(26) ]
n = defaultdict(int)
for c in s:
n[c] += 1
n_max = max( n.values() )
C = [
[0] * (n_max+1) for _ in range(n_max+1)
]
for i in range(n_max+1):
C[i][0] = 1
for j in range(1, n_max+1):
for i in range(1, n_max+1):
C[i][j] = C[i-1][j-1] + C[i-1][j]
total_count = 0
for k in range(1, n_max+1):
count = 1
for c in alphabet:
if n[c] < k:
continue
count *= (C[n[c]][k] + 1)
count -= 1
total_count = (total_count + count) % mod
return total_count
Since a subproblem only depends on previous and current columns, we can keep track of 2 columns worth of
Time: 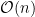
class Solution:
def countGoodSubsequences(self, s: str) -> int:
mod = pow(10, 9)+7
alphabet = [ chr( ord('a')+offset ) for offset in range(26) ]
n = defaultdict(int)
for c in s:
n[c] += 1
n_max = max( n.values() )
C = [
[0, 0] for _ in range(n_max+1)
]
for i in range(n_max+1):
C[i][0] = 1
prev, curr = 0, 1
total_count = 0
for k in range(1, n_max+1):
C[0][curr] = 0
for i in range(1, n_max+1):
C[i][curr] = C[i-1][prev] + C[i-1][curr]
count = 1
for c in alphabet:
if n[c] < k:
continue
count *= (C[n[c]][curr] + 1)
count -= 1
total_count = (total_count + count) % mod
prev, curr = curr, prev
return total_count
From factorials
We can use the direct definition of n-choose-k: 
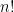


Subproblem

Since our mod, 
Fermat’s Little Theorem: If 




str size is limited to 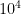


Let 


We precompute factorials and 

Time:
class Solution:
def compute_modular_factorials(self, n: int, mod: int) -> List[int]:
fact = [0] * (n+1)
fact[0] = 1
for i in range(1, n+1):
fact[i] = (i * fact[i-1]) % mod
return fact
def compute_modular_exp(self, x: int, n: int, mod: int) -> int:
exp = 1
while n > 0:
half_n, is_odd = divmod(n, 2)
if is_odd:
exp = (exp * x) % mod
x = (x * x) % mod
n = half_n
return exp
def compute_modular_inv(self, fact: List[int], mod: int) -> List[int]:
n = len(fact)-1
inv = [0] * (n+1)
inv[n] = self.compute_modular_exp( fact[n], mod-2, mod )
for i in range(n-1, -1, -1):
inv[i] = (inv[i+1] * (i+1)) % mod
return inv
def choose(self, n: int, k: int, fact: List[int], inv: List[int]) -> int:
if k == 0:
return 1
if n == 0:
return 0
return fact[n] * inv[k] * inv[n-k]
def countGoodSubsequences(self, s: str) -> int:
mod = pow(10, 9)+7
alphabet = [ chr( ord('a')+offset ) for offset in range(26) ]
n = defaultdict(int)
for c in s:
n[c] += 1
n_max = max( n.values() )
fact = self.compute_modular_factorials( n_max, mod )
inv = self.compute_modular_inv( fact, mod )
total_count = 0
for k in range(1, n_max+1):
count = 1
for c in alphabet:
if n[c] < k:
continue
count *= ( self.choose(n[c], k, fact, inv) + 1 )
total_count = (total_count + (count-1)) % mod
return total_count

Leave a comment